Machine Learning & Big Data : des dangers pour les logiciels libres ?
· Vincent Jousse
Ou vous sortez de votre grotte ou vous avez forcément entendu parler de ces deux mots fourre-tout « big data ». En gros, les informaticiens (mais aussi et surtout les personnes du marketing) ont tendance à l'utiliser dès qu'il faut traiter un peu plus de deux lignes de données avec un programme informatique : autant dire tout le temps. C'est à la mode, ça fait bien en société et ça permet d'obtenir des financements French Tech.
À côté de ça, de réelles technologies dont vous ne pouvez plus vous passer sont basées sur ces concepts de « big data » et de « machine learning » (apprentissage artificiel) : la reconnaissance de la parole, les filtres anti-spam, la recherche d'images, la traduction automatique, j'en passe et des meilleurs. Et tout ça pourrait bien avoir de très lourdes répercutions sur notre avenir.
Les logiciels libres
Vous ne le savez peut-être pas, mais les logiciels libres sont partout. Tous les sites que vous consultez au quotidien sont basés sur des logiciels libres (Twitter, Facebook, Google, …), les logiciels de vos téléphones sont construits à partir de briques libres, vous pouvez aller sur Internet grâce aux logiciels libres.
Rien de ce que l'on connait aujourd'hui n'aurait été possible sans le logiciel libre. Si Richard Stallman n'avait pas initié le mouvement au début des années 80, le monde serait alors très différent.
Mais qu'est-ce qu'un logiciel libre au juste ? C'est beaucoup de choses à la fois (notamment un logiciel que l'on peut librement modifier et dupliquer), mais de mon point de vue, c'est surtout une vision du monde : croire que l'avenir se construit en partageant plutôt qu'en gardant pour soi.
J'aime cette vision du monde. J'aime me dire qu'un jour chaque personne, chaque entreprise, aura plutôt intérêt à partager qu'à garder pour soi. Notre modèle capitaliste actuel va totalement à l'encontre de ça, mais le logiciel libre est un exemple concret que ce n'est pas irréalisable.
Le big data et l'apprentissage artificel
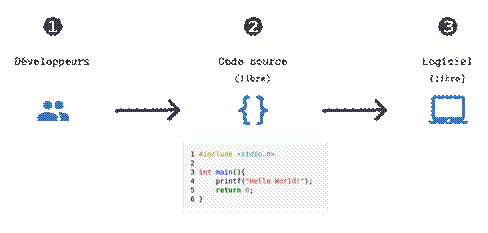
Vous allez me dire, que vient faire le big data ici ? Jusqu'ici, la valeur ajoutée des logiciels se situait dans le code source qui était produit par le(s) développeur(s) du logiciel lui-même. Ce code source, qui peut être mis sous licence libre, vous permet de vous servir du logiciel. Grâce au code de Firefox ou de Chrome (et donc grâce au logiciel du même nom qui en découle), vous pouvez aller sur Internet. Grâce au code de Linux, vous pouvez utiliser vos téléphones Androïd.
Ce type de logiciel dont toute la valeur ajoutée (ou presque) dépend uniquement des lignes de code tapées par le développeur se prête très bien au monde du libre. Il suffit d'un développeur talentueux pour initier un projet et il est ensuite assez aisé de contribuer à plusieurs à distance sur ce même logiciel.
C'est aussi simple que ça.
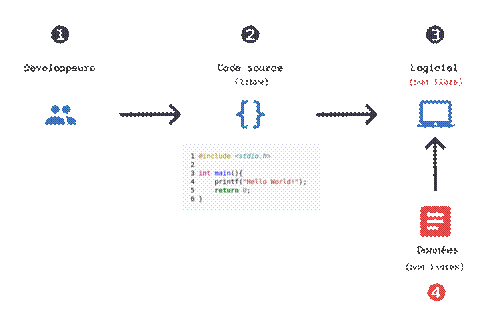
Mais ces dernières années, une nouvelle vague de logiciels a vu le jour. Une partie de la valeur ajoutée du logiciel se situe toujours dans le code source, mais la plus grosse partie se situe maintenant dans les données que traite ce logiciel pour vous fournir ses fonctionnalités. Et c'est là que le bât blesse.
Le monde des données
Une grosse partie des logiciels fonctionnant sur la base de machine learning ont besoin de beaucoup données. Si l'on veut vulgariser un peu, il faut qu'un humain annote des données manuellement pour dire à la machine ce qu'elle devrait trouver à partir de ces données. Pour la transcription de la parole par exemple, il faut fournir au système des centaines d'heures (à minima) d'enregistrements transcrits par des humains pour qu'il puisse apprendre comment produire lui-même ce type de transcription sur des données qu'il n'aura jamais vues.
En fonction du logiciel, ces données peuvent être de plusieurs natures :
· Des fichiers textes alignés en langue source / langue cible pour la traduction de la parole
· Des images annotées avec ce qu'elles contiennent pour la reconnaissance d'image
· Des fichiers audio/vidéo transcrits pour la reconnaissance de la parole
· Vous voyez le principe ?
Lorsque ces ressources sont accessibles, elles ne le sont généralement pas librement. Les mondes de l'audio, de la vidéo, de l'image et même du texte sont rongés par le copyright, les fameux : « touche pas à mon travail ou je me fâche tout rouge » ou encore « prems et pas toi nananèèèère ! ».
En gros, seuls ceux qui peuvent payer ont le droit d'utiliser ces données. Ça exclut généralement le monde du logiciel libre où la plupart du travail est bénévole.
Mais dans le coup, on risque d'avoir un sérieux problème non ? D'un côté on a des logiciels libres qui contribuent depuis des décennies au bien commun et de l'autre côté des données indispensables pour qu'ils fonctionnent, mais qui ne sont pas disponibles librement.
Un cas concrêt : reconnaissance de la parole en français
Prenons un cas concrêt que je connais bien de part mon parcours professionnel : la reconnaissance de la parole, et plus particulièrement la reconnaissance de la parole en français. Mais le principe est certainement généralisable à d'autres domaines similaires utilisant du « machine learning » et du « big data ».
Si actuellement vous souhaitez utiliser une solution libre de reconnaissance automatique de la parole performante en français pour transcrire vos audios/vidéos, c'est impossible (performante comme ça). Pas à cause d'un souci logiciel bien sûr, eux ils sont disponibles depuis plus de dix ans librement (actuellement le plus utilisé est Kaldi, par le passé c'était Sphinx).
Le souci est bien un souci de données. Pour apprendre un tel système, il faut des données, beaucoup de données : de 300H à plus de 1000H transcrites à la main.
Nous pourrions partir du fait qu'avec une communauté open-source bien organisée, nous pourrions transcrire 300H d'audio à la main. Ça représente environ 2000H de travail avec des personnes très compétentes en français, ce qui n'est quand même pas négligeable.
Quand bien même serait-il possible de transcrire ces 300H+ d'audio, il reste un souci : la propriété des données. Comme les images que vous trouvez sur internet, les vidéos et les audios que vous trouvez ne sont généralement pas libres de droit. Il est donc impossible d'apprendre un système de reconnaissance automatique de la parole avec.
Exit donc la plupart des vidéos Youtube, des podcast de radio, des émissions de télé. Ça fait qu'il n'en reste pas lourd.
Et donc ?
Il est donc important de comprendre que le nerf de la guerre, c'est maintenant les données. C'est très vrai pour les entreprises, ça l'est encore plus pour le monde du logiciel libre. Les entreprises peuvent mettre les moyens, le monde du logiciel libre beaucoup moins.
Notre monde informatique actuel a été façonné grâce aux logiciels libres. Il serait dommage de manquer le virage du monde informatique de demain en le laissant dans l'unique main d'entreprises ou d'organismes privés.
Je n'ai pas de réponse immédiate à ces problématiques, mais je pense qu'il est important que la communauté du logiciel libre dans son ensemble en soit consciente.
Peut-être pourrions-nous créer ce que Framasoft est pour le logiciel, mais pour les données : une association/organisation qui s'assure que le monde du libre propose une alternative aux géants qui ont l'argent pour avoir des données à ne plus savoir qu'en faire. Aller plus loin que ce qui se fait sur l'OpenData en France actuellement en créant de la donnée à destination des systèmes d'apprentissage automatique.
Peut-être que l'ANR (Agence Nationale de la Recherche) devrait forcer toutes les données qui sont financées par notre argent à être disponibles sous licence libre de droit ? Régulièrement, l'ANR orchestre des campagnes d'évaluation des systèmes, et il ne me semblerait pas idiot que les données qui en sont issues soient mises à disposition du plus grand nombre (c'est le cas pour certaines mais pas pour toutes).
Peut-être contacter tous les laboratoires de recherche francophones des différents domaines et voir avec eux ce qu'ils pourraient mettre à disposition librement ?
Même si la plupart d'entre nous sont nés dans un monde où le logiciel libre était quelque chose de normal, ça n'a pas toujours été le cas, et ça risque de ne plus l'être si l'on n'y prête pas suffisamment attention.
Intéressé pour en discuter ? N'hésitez pas à me contacter directement sur Twitter @vjousse ou sur Mastodon @vjousse.
Collé à partir de <http://vincent.jousse.org/blog/les-dangers-du-big-data-pour-les-logiciels-libres/>